
如今,人工智能是一个如此大的话题,以至于OpenAI和LangChain等库几乎不需要任何介绍。然而,如果你在过去一年左右的时间里迷失在另一个维度中,简而言之,LangChAIn是一个用于开发由语言模型驱动的应用程序的框架,允许开发人员使用LLM和AI的力量来分析数据并构建自己的AI应用程序。
使用案例
在讨论所有技术细节之前,我认为最好先看看使用 LangChain 进行文本数据集分析的一些用例。以下是一些示例:
系统地从长文档中提取有用的数据。
可视化文本或文本数据集中的趋势。
对冗长而无趣的文本进行总结。
先决条件
要按照本文的操作,请创建一个新文件夹并使用 pip 安装 LangChain 和 OpenAI:
pip3 install langchain openai
文件读取、文本拆分和数据提取
要分析大型文本(如书籍),您需要将文本拆分为较小的块。这是因为大型文本(例如书籍)包含数十万到数百万个令牌,并且考虑到没有 LLM 可以一次处理这么多令牌,因此没有办法在不拆分的情况下将此类文本作为一个整体进行分析。
此外,与其为每个文本块保存单独的提示输出,不如使用模板提取数据并将其转换为 json 或 CSV 等格式会更有效。
在本教程中,我将使用 JSON。我从古腾堡计划免费下载。这段代码阅读了弗里德里希·尼采 (Friedrich NIEtzsche) 的《超越善恶》一书,将其分成几章,对第一章进行了总结,提取了文本中呈现的哲学信息、伦理理论和道德原则,并将其全部放入 JSON 格式。
正如你所看到的,我使用“GPT-3.5-turbo-1106”模型来处理多达 16000 个令牌和 0.3 温度的更大上下文,以赋予它一点创造力。您可以对温度进行试验,看看哪种温度最适合您的用例。
注意:温度参数决定了LLM做出创造性答案的自由度,有时甚至是随机答案。温度越低,LLM 输出越真实,温度越高,LLM 输出越有创意和随机性。
提取的数据使用和提供的 jsON 模式放入 JSON 格式:create_structured_output_chain
json_schema = { "type": "Object", "properties": { "summary": {"title": "Summary", "description": "The chapter summary", "type": "string"}, "messages": {"title": "Messages", "description": "Philosophical messages", "type": "String"}, "ethics": {"title": "Ethics", "description": "Ethical theories and moral PRinciples presented in the text", "type": "string"} }, "reqUIred": ["summary", "messages", "ethics"], } chain = create_structured_output_chain(json_schema, llm, prompt, verbose=false)
然后,代码读取包含该书的文本文件,并将其按章节拆分。然后,该链被赋予本书的第一章作为文本输入:
f = open("texts/Beyond Good and Evil.txt", "r")
phi_text = str(f.read())
chapters = phi_text.split("CHAPTER")
print(chain.run(chapters[1]))下面是代码的输出:
{'summary': 'The chapter discusses the concept of utilitarianism and its APPlication in ethical decision-making. It explores the idea of maximizing overall happiness and minimizing suffering as a moral principle. The chapter also delves into the criticisms of utilitarianism and the challenges of applying it in real-world scenariOS.', 'messages': 'The chapter emphasizes the importance of considering the consequences of our actions and the well-being of all individuals affected. It encourages thoughtful and empathetic decision-making, taking into account the broader impact on society.', 'ethics': 'The ethical theories presented in the text include consequentialism, hedonistic utilitarianism, and the principle of the greatest good for the greatest number.'}现在,您可以对所有章节执行相同的操作,并使用此代码将所有内容放入 JSON 文件中。
我添加了评论,因为在处理大型文本时,您可能会达到速率限制,如果您拥有 OpenAI API 的免费套餐,则最有可能。由于我认为知道您在请求中使用了多少代币和积分很方便,以免意外耗尽您的帐户,因此我还曾经查看每章使用了多少代币和积分。time.sleep(20)with get_openai_callback() as cb:
这是分析每个章节并将每个章节的提取数据放在共享 JSON 文件中的代码部分:
for chi in range(1, len(chapters), 1):
with get_openai_callback() as cb:
ch = chain.run(chapters[chi])
print(cb)
print("\n")
print(ch)
print("\n\n")
json_object = json.dumps(ch, indent=4)
if chi == 1:
with open("Beyond Good and Evil.json", "w") as outfile:
outfile.write("[\n"+json_object+",")
elif chi < len(chapters)-1:
with open("Beyond Good and Evil.json", "a") as outfile:
outfile.write(json_object+",")
else:
with open("Beyond Good and Evil.json", "a") as outfile:
outfile.write(json_object+"\n]")索引从 1 开始,因为第 0 章之前没有第 1 章。如果索引为 1(在第一章中),则代码会将 JSON 数据写入(覆盖任何现有内容)到文件中,同时在开头添加左方括号和换行符,并在末尾添加逗号以遵循 JSON 语法。如果不是最小值 (1) 或最大值 (),则 JSON 数据将与末尾的逗号一起添加到文件中。最后,如果达到最大值,则 JSON 将添加到 JSON 文件中,并带有新行和右方括号。chichichilen(chapters)-1chi
代码运行完毕后,你会看到其中充满了从所有章节中提取的信息。Beyond Good and Evil.json

下面是此代码工作原理的直观表示形式:
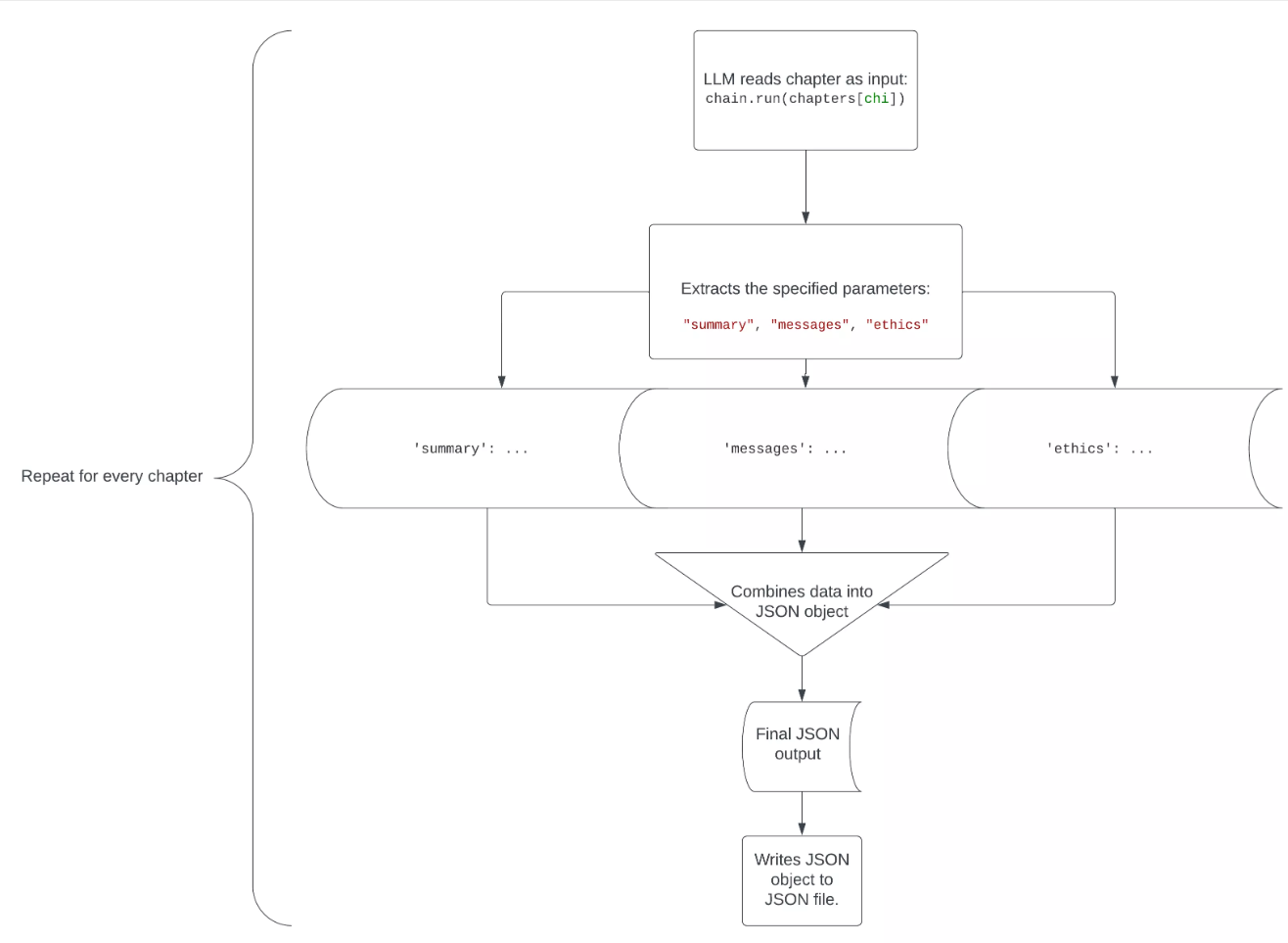
使用多个文件
如果你有几十个单独的文件要逐个分析,你可以使用一个类似于你刚才看到的脚本,但它不是遍历章节,而是遍历文件夹中的文件。
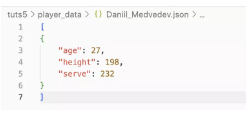
我将使用一个文件夹的例子,该文件夹充满了排名前 10 位的网球运动员(截至 3 年 2023 月 <> 日)的维基百科文章,名为 .您可以在此处下载该文件夹。这段代码将读取每篇维基百科文章,提取每个球员的年龄、身高和最快发球(公里/小时),并将提取的数据放入一个名为 .top_10_tennis_playersplayer_data
下面是提取的玩家数据文件的示例。
但是,这段代码并不是那么简单(我希望是这样)。为了高效可靠地从文本中提取最准确的数据,这些文本通常太大而无法在不进行块拆分的情况下进行分析,我使用了以下代码:
from langchain.text_splitter import RecursivecharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( chunk_size=16000, chunk_overlap=2000, length_function=len, add_start_index=True, ) sub_texts = text_splitter.create_documents([player_text]) ch = [] for ti in range(len(sub_texts)): with get_openai_callback() as cb: ch.append(chain.run(sub_texts[ti])) print(ch[-1]) print(cb) print("\n") # time.sleep(10) if you hit rate limits for chi in range(1, len(ch), 1): if (ch[chi]["age"] > ch[0]["age"]) or (ch[0]["age"] == "not found" and ch[chi]["age"] != "not found"): ch[0]["age"] = ch[chi]["age"] break if (ch[chi]["serve"] > ch[0]["serve"]) or (ch[0]["serve"] == "not found" and ch[chi]["serve"] != "not found"): ch[0]["serve"] = ch[chi]["serve"] break if (ch[0]["height"] == "not found") and (ch[chi]["height"] != "not found"): ch[0]["height"] = ch[chi]["height"] break else: continue
实质上,此代码执行以下操作:
它将文本拆分为大小为 16000 个标记的块,块重叠为 2000 个,以保持一些上下文。
它从每个块中提取指定的数据。
如果从最新区块中提取的数据比第一个区块的数据更相关或更准确(或者在第一个区块中找不到值,但在最新区块中找到该值),则它会调整第一个区块的值。例如,如果块 1 说,块 2 说,该值将更新为 27,因为我们需要玩家的最新年龄,或者如果块 1 说,块 2 说,该值将更新为 232,因为我们正在寻找最快的发球速度。
'age': 26'age': 27age'serve': 231'serve': 232serve
以下是整个代码在流程图中的工作方式。
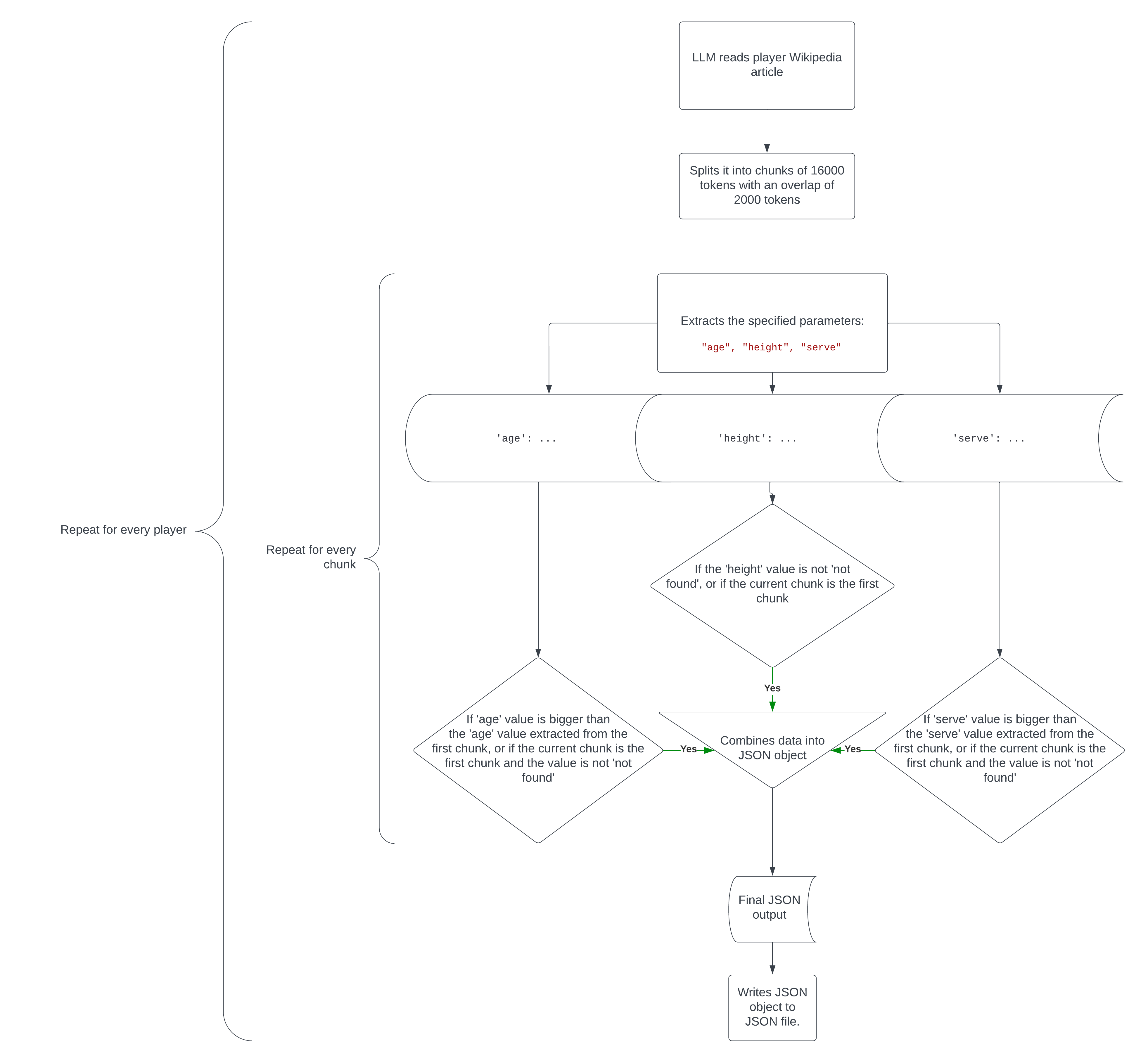
文本到嵌入
嵌入是用于将文本片段相互关联的向量列表。
LangChain中文本分析的一个重要方面是在大型文本中搜索与特定输入或问题相关的特定块。
我们可以回到弗里德里希·尼采(Friedrich Nietzsche)的《超越善恶》(Beyond Good and Evil)一书中的例子,并制作一个简单的脚本,对文本提出一个问题,例如“哲学家的缺陷是什么?”,将其转换为嵌入,将本书分成章节,将不同的章节转换为嵌入,并找到与探究最相关的章节。 建议应该阅读哪一章才能找到作者所写的这个问题的答案。您可以在此处找到执行此操作的代码。特别是此代码,用于搜索给定输入或问题最相关的章节:
embedded_question = embeddings_model.embed_query("What are the flAWS of philosophers?") similarities = [] tags = [] for i2 in range(len(emb_list)): similarities.Append(cosine_similarity(emb_list[i2], embedded_question)) tags.append(f"CHAPTER {i2}") print(tags[similarities.index(max(similarities))])
每个章节和输入之间的嵌入相似性被放入一个列表()中,每个章节的数量被放入列表中。然后使用 打印最相关的章节,从列表中获取与列表中的最大值相对应的章节编号。similaritiestagsprint(tags[similarities.index(max(similarities))])tagssimilarities
输出:
CHAPTER 1
下面是此代码的可视化工作方式。
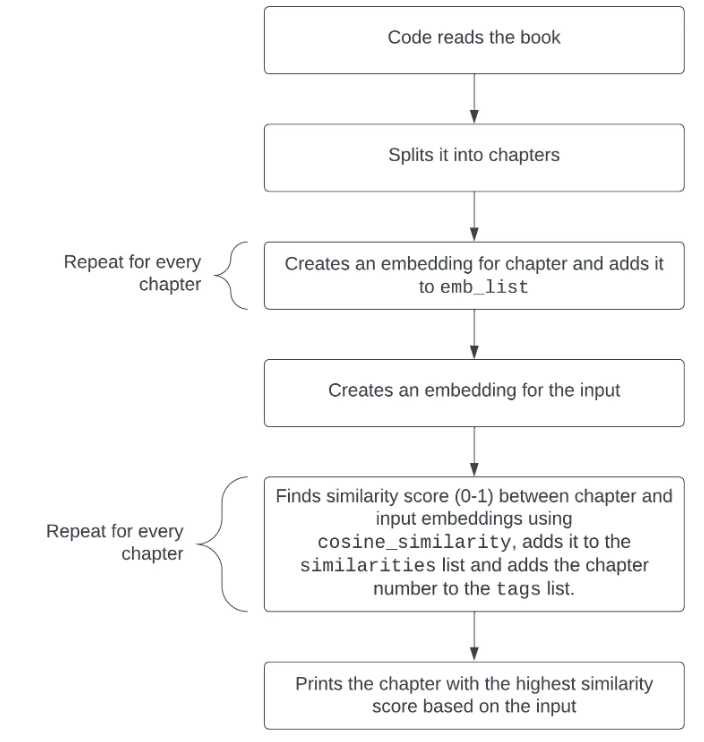
其他应用思路
LangChain 和 LLM 的大型文本还有许多其他分析用途,尽管它们太复杂而无法在本文中完整介绍,但我将在本节中列出其中的一些并概述如何实现它们。
可视化主题
例如,您可以获取与 AI 相关的 YouTube 视频的转录,例如此数据集中的视频,提取每个视频中提到的 AI 相关工具(LangChain、OpenAI、tensorflow 等),将它们编译成一个列表,并找到整体上最常提到的 AI 工具,或者使用条形图来可视化每个工具的受欢迎程度。
分析播客成绩单
您可以获取播客成绩单,例如,找出不同嘉宾之间对给定主题的看法和情绪的相似之处和不同之处。您还可以制作一个嵌入脚本(如本文中的脚本),该脚本根据输入或问题在播客脚本中搜索最相关的对话。
分析新闻文章的演变
有很多大型新闻文章数据集,比如BBC新闻标题和描述的数据集,以及财经新闻标题和描述的数据集。使用此类数据集,您可以分析每篇新闻文章的情绪、主题和关键字等内容。然后,您可以直观地看到新闻文章的这些方面如何随时间演变。
结论
我希望你觉得这很有帮助,并且你现在对如何使用不同的方法(如嵌入和数据提取)在 Python 中使用 LangChain 分析大型文本数据集有所了解。祝你的LangChain项目好运!



网友评论文明上网理性发言 已有0人参与
发表评论: